Gone in 60 Seconds - Cloud Load Balancing Timeouts
- Published on
- Reading time
- Authors

- Name
- Simon Waight
- Mastodon
- @simonwaight
Update: July 2014: AWS announced that customers can now manage ELB timeouts. Read more here: https://aws.amazon.com/blogs/aws/elb-idle-timeout-control/
After what seems like ages we finally managed to get to the bottom of the weird issues we were having with a load balanced instance of Umbraco hosted at Amazon Web Services. Despite having followed Umbraco's load balancing guide and extensively tested we were seeing some weird behaviours for multi-page publishing and node copy operations. Multiple threads were created for each request which lead to unexpected outcomes for users.
Eventually we managed to isolate this to the default (and unchangeable at time of writing) 60 second timeout behaviour of AWS' ELB infrastructure combined with the long-running nature of the POST requests from Umbraco. The easiest way to see the real side effect of the 60 second timeout is to put a debugging proxy like Fiddler or Charles between your browser and the ELB. What we saw is below.
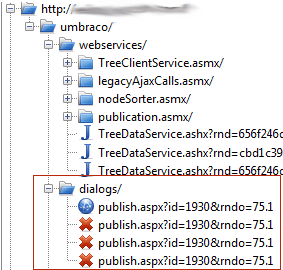
So, you can see the culprit right there in the red square – the call to the publish.aspx page is terminated at 60 seconds by the ELB which causes the browser to resubmit it – Ouch! This also occurs when you copy or move nodes and the process exceeds 60 seconds – you get multiple nodes!
To be clear – this is not a problem that is isolated to Umbraco – there is a lot of software that relies on long-running HTTP POST operations with the expectation that they will run to completion.
Now there are probably a range of reasons why AWS has this restriction – the forum posts (dating back to 2009) don't enlighten but it's not hard to see why, in an "elastic" environment anything that takes a long time to complete may be a bad thing (you can't "scale up" your ELB if it's still processing a batch of long-running requests). I can see the logic to this restriction – it simplifies the problems the AWS engineers need to solve, but it does introduce a limitation that isn't covered clearly enough in any official AWS documentation.
The real solution here has to come from better software design that takes into account this limitation of the infrastructure and makes use of patterns like Post-Redirect-Get to submit a short POST request to initiate the process on the server, redirect to another page and then utilise async calls from the browser to check on the status of the process.
Yes, I know, we could probably run our own instances with HA Proxy on, but why build more infrastructure to manage when what's there is perfectly fit for purpose?
Updated - You Have An Alternative
10 September - I've been lucky enough to be attending the first AWS Achitecture course run by Amazon here in Sydney and the news on this front is interesting. By default you get 60 seconds, *but* you can request (via your AWS Account Manager or Architect) that this timeout be increased up to 17 minutes maximum. This is applied on a per-ELB basis so if you create more ELB instances you would need to make the same request to AWS.
My advice: fix your application before you ask for a non-standard ELB setup.
Update: July 2014: AWS announced that customers can now manage ELB timeouts. Read more here: https://aws.amazon.com/blogs/aws/elb-idle-timeout-control/
Not Just For AWS ELB
Now, chaps (and ladies), you also need to be aware that this issue will raise its head in Windows Azure as well but most likely after a longer duration. A very obliquely written blog post on MSDN suggests it will be now be based on the duration AND the number of concurrent connections you have.
You have been warned!