How to port AWS Serverless solutions to Microsoft Azure
- Published on
- Reading time
- Authors

- Name
- Simon Waight
- Mastodon
- @simonwaight
Avoid Vendor Lock-in.
Three words. I wonder how many hours (days, weeks, months?) have been lost to designing and building software solutions and systems to the lowest common denominator simply to avoid the perceived risk of betting on the wrong platform?
While risk mitigation and extensibility should form a part of any design, I've believed for a while now, especially since the rise of modern cloud platforms, that the need to build abstractions in solutions simply to avoid perceived future risk is a massive sinkhole and a large inhibitor to innovation, especially in the enterprise.
Imagine, if you will, designing and building a solution that makes direct use of SDKs and platform features provided by a cloud vendor. Compare this to building the same solution, but instead of using the SDKs or features directly you first wrap them in abstractions. It's easy to see the amount of additional effort involved in the second scenario.
If you consider the amount of non-functional development work required in scenario two and it's impact of this work on delivery time and cost along with potential reduction in overall functional capabilities of the resulting solution you can see it can be a fairly large impact. Also consider this in the context that at some future point (let's say 3 years from now) you might need to move to a different platform.
There are an absolute minority of businesses that might require true multi or hybrid cloud solutions (👋 Kubernetes), but I can tell you nobody at Netflix has lost sleep over their bet on a single cloud vendor.
I firmly believe that you can, in many cases, push re-platforming risk into the future. Any cloud migration will invariably be a multi-step process that involves infrastructure, data and application code. While you don't want to rewrite your entire application codebase, if all you need to do is rewrite code that is tightly coupled to a cloud API then your overall effort is relatively small, and can likely be factored into the costs of migration.
Anyhow, enough of my opinions, let's look at a practical example.
List Manager Event-driven sample
AWS has a few sample Lambda applications on their documentation site, and I thought I would find the most intricate one and use it as the basis for the demo code to go along with this blog. To that end I chose the List manager sample application for AWS Lambda as my preferred demo.
I also wanted to select a Lambda solution because it's the most tightly bound to the cloud platform it is running on. Almost every aspect of this sample application relies on a piece of AWS that is available on AWS only - the two items that are not are the Node.js code containing the business logic along with the RDS MySQL instance which is just a managed MySQL service.
Switching to Azure
If we're starting with serverless, we might as well target serverless! In most inter-cloud migrations I'd expect this type of mapping to occur given the level of equivalence in services between vendor lock-in is really not a factor any more.
Yes, we'll have to change some SDKs and libraries that determine how we interact with as-a-Service offerings, but at the core there is not much business logic that needs to change.
If you want simply to see the source code you can check it out on GitHub, otherwise read on for how the migration was completed.
Here's a high level architecture diagram to give you a feel for what we're aiming for.
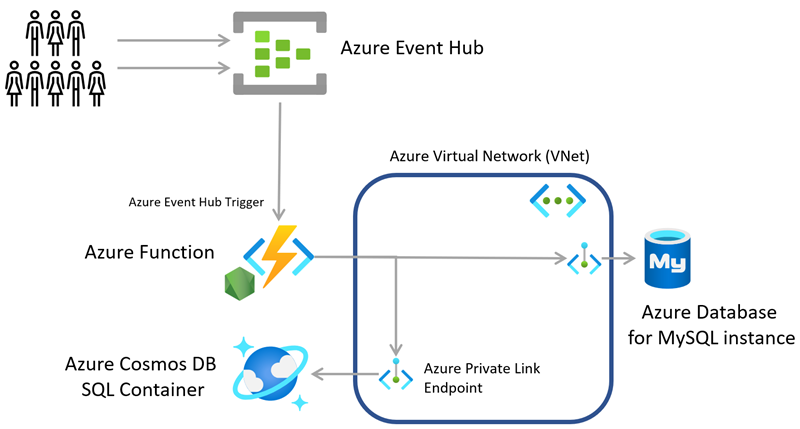
The porting process
The only bits we really need to keep from the original are the Node.js logic implementations and the format and data for the events driving the solution. Everything else is just supporting infrastructure which we can replace.
The original sample uses private networking to connect everything except the event source, so we can easily rebuild the infrastructure from scratch in Azure. However, rather than starting with this, as I will assume it's just a secure pipe between PaaS in Azure, I'm more interested in porting the Node.js and event source code so I can have an end-to-end test that allows me to validate my Azure implementation.
At this point I could easily have run the Cosmos DB emulator and a MySQL Server on my developer box to act as surrogates for their Azure equivalents and developed the Azure Functions using Visual Studio Code and the Azure Core Functions tooling.
However, I didn't want to setup MySQL locally, and running it all in Azure is just handier 🙂 - especially as I'd still need to use an actual Azure Event Hub for my testing. I did develop the Functions locally and then connected them directly to Azure as required. If I'd spun up the development infrastructure to use private networking I'd need to do this development on a Virtual Machine running on the same network - something that just felt unnecessary at this point.
So, with all these pieces in place I began working on the Node.js Functions and converted them to use Azure. The 'dbadmin' Function really needed a change as the source sample allows any arbitrary SQL query to be sent to this Function - something that strikes me as massively dangerous. I solved this by hardcoding the SQL that can be used and controlling any variables via only Azure Functions or Azure Key Vault configuration values that are only ever used on the server and never exposed to any client.
The 'processor' Function was a little more work, not helped by me not being a massively experienced Node developer, and the need to update code to better handle Node Promises, as well as the differences between Cosmos DB and DynamoDB. From what I can see it looks like DynamoDB accepts and emits JSON as simple strings, whereas Cosmos DB (or its Node SDK) readily accepts and emits JSON objects ready for code to consume. Additionally, Cosmos DB has the idea of an 'upsert', which does seem to exist in DynamoDB, but is not used in the source application codebase at all.
The final difference between Cosmos DB and DynamoDB is the concept of a Table. Cosmos DB doesn't have a Table construct, and the anti-patten a lot of first time Cosmos DB users fall into is to map a Table (typically from a relational data model world) into a Cosmos DB Container. At first glance this looks like a good fit, but it's actually likely to cause you pain (mostly around cost, but potentially also performance).
Cosmos DB stores JSON documents, and each document can have a different set of properties. While you are required to meet a few basic rules including having an identity field with high cardinality (basically the field should have a lot of different possible values) you can otherwise store multiple different document types in one Container, which is what I've done with this sample.
Once I had everything working end-to-end with this hybrid development setup it was then time to build out the final infrastructure deployment which requires private networking.
The easiest way I find to achieve infrastructure modelling is to use the Azure Portal. This is because it hides a lot of complexity in the underlying REST APIs being used to provision the infrastructure and it also provides me with an easy way to discover required attributes to provision infrastructure I may not have worked with previously. There were a few items in this demo that I knew of, but hadn't used, so this worked out perfectly. I'd also note I didn't look at the exiting CloudFormation definitions and try and convert those. What I actually did was use the documentation and diagram on the source GitHub repository as my guide - proving to me that solid existing documentation is key to any migration!
Now with the baseline environment in place I exported the deployment to an ARM template so I could create a reusable template to go into my GitHub sample. I've been meaning to learn Bicep for a while now, so I took the opportunity to decompile the ARM template into Bicep which did a pretty good job. I suspect the resulting Bicep definition is overly verbose because it contains a lot of properties with default values that could be removed, but I'm pleasantly surprised at how I could do things like define Storage Account Containers, Cosmos DB Databases and Containers, Key Vault secrets, and a whole range of other things that used to be manual steps. It took me a little while to convert the Bicep into a re-usable template, but I'm pretty happy with the result which also now supports comments!
Once I had the infrastructure deployed I used the Azure Functions Deployment Center to setup a GitHub Action for my deployment. This simple process creates the necessary Secret in GitHub to enable the deployment and also results in a GitHub Action workflow embedded in my sample repository which can easily be forked and cloned as required by others.
Finally, I could sit down and document the sample both on GitHub and via this blog.. so here we are! 😎
Rather than wrap shell scripts around all the commands needed for the sample I've tried to expose the raw Azure CLI commands you'd need to use. They aren't actually that complex and really show the level of consistency the Azure CLI has and how straightforward it is to work with!
Future bets
So if you've stuck it out this far... thanks for that!
The process for this blog has been a fun one, but I do think there will be a better way forward with at least some aspects of these types of solutions in future.
Containerisation and Kubernetes offer great platform-agnostic ways for hosting solution components, even if not all solution components live within a portable environment. This also doesn't mean you need start with this as an option either!
The Azure Functions runtime has been portable since its v2 release and can be run on Azure, on-premises or anywhere you can run a Container. Additionally, I see the work Microsoft is doing around Kubernetes Extensions such as the Azure App Services on Kubernetes and I start to see ways for people to have confidence that they can build solution components once and then have flexibility on where they host them, without needing to do a huge amount of porting work.
Broadening cloud hosted services to provide access to popular technologies like MySQL, Postgres, MongoDB, Redis, Grafana, et al, also means over time you will have confidence that you can truly take your solutions anywhere!
Happy Days! 😎
P.S. You can check out the List Manager Azure sample on GitHub.