Analysing git commit history using Azure Data Explorer
- Published on
- Reading time
- Authors

- Name
- Simon Waight
- Mastodon
- @simonwaight
Regardless of where your git repositories are hosted, there is always a need to have visbility over what's going on in them. While hosted services like GitHub provide metrics APIs, there are some limitations around those metrics APIs, particularly for busy or large repositories. In this post I'm going to look at how you can use Azure Data Explorer to analyse the commit history for a git repository.
Getting started
In order to generate the data required for analysis you must have a copy of your target repository cloned somewhere you can run git commands against it. Once you have done that you can use the following commands to get the data you require for the remainder of the process.
As my demonstration repository I am going to use the .NET open source GitHub repository.
Export commit history as JSON
The following (long) command exports commit history in a JSON format. You'll note that I haven't included the body and subject fields which can be problematic to parse when embedded in JSON. They don't provide useful data for the scenario we are exploring either, so out they go!
This snippet, and the following one, are based on those that come with the excellent blog post on importing git history into Elasticsearch and its related GitHub repositry.
git log --pretty=format:'{%n "commit": "%H",%n "abbreviated_commit": "%h",%n "tree": "%T",%n "abbreviated_tree": "%t",%n "parent": "%P",%n "abbreviated_parent": "%p",%n "refs": "%D",%n "encoding": "%e",%n "sanitized_subject_line": "%f",%n "commit_notes": "%N",%n "verification_flag": "%G?",%n "signer": "%GS",%n "signer_key": "%GK",%n "author": {%n "name": "%aN",%n "email": "%aE",%n "date": "%aD"%n },%n "committer": {%n "name": "%cN",%n "email": "%cE",%n "date": "%cD"%n }%n},' | sed "$ s/,$//" | sed ':a;N;$!ba;s/\r\n\([^{]\)/\\n\1/g' | awk 'BEGIN { print("[") } { print($0) } END { print("]") }' > history.json
Note: this command will only export commit history for the currently selected branch. If you have busy branches in your repository, consider exporting the history for them as discreet datasets.
Export file change history to CSV
Our previous command gave us the metadata for commits, but it didn't include details of the file changes that happened as part of each commit. For that we can use the below command to export the file changes to a text file.
git --no-pager log --name-status > files.txt
Once we have this text file we then need to prepare it for import into Azure Data Explorer by flattening the structure and keeping only what we need. For this purpose I wrote a small C# utility that will accept the files.txt file and output a flattened CSV for import. See the readme file in the repository for details on how to use.
Import files into Azure Data Explorer
Let's start by spinning up a new Azure Data Explorer cluster and database. For the purpose of this post I'm going to use the dev/test tier of the service, something which will easily handle the data, even for a busy repository like the .NET one (though I note we're just looking at the main branch).
Notes:
- Microsoft currently offers a 12 month free tier for Azure Data Explorer. Before spinning up a cluster, check to see if you are able to create a free one.
- By default Azure Data Explorer clusters auto-stop after 5 days, though you can manually stop them at any time. Stopped clusters incur only storage charges, stretching your money further! 😁
First, let's create our Azure Data Explorer cluster using the Azure CLI. Note that you need to use the (at time of writing) experimental commands for Kusto clusters. If you try the old deprecated commands they will fail.
az kusto cluster create --name gitcommitanalysis \
--sku name="Dev(No SLA)_Standard_D11_v2" capacity=1 tier="Basic" \
--resource-group gitanalysisdemo \
--location westus3
Once the cluster is created, you can go ahead and create an empty database.
az kusto database create --cluster-name gitcommitanalysis \
--database-name github-dotnet \
--read-write-database location="westus3" \
--resource-group gitanalysisdemo
At this stage you are now ready to import the files you created earlier into Azure Data Explorer. At present there's no way to import files from the Azure CLI, though you can use the KQL (Kusto Query Langauge) ingest from storage feature if you'd like. To keep this post simple, we're going to create tables via the Azure Portal.
Navigate to our newly created Azure Data Explorer instance in the Azure Portal and in the left navigation select Query and in the window that shows select Open in Web UI.
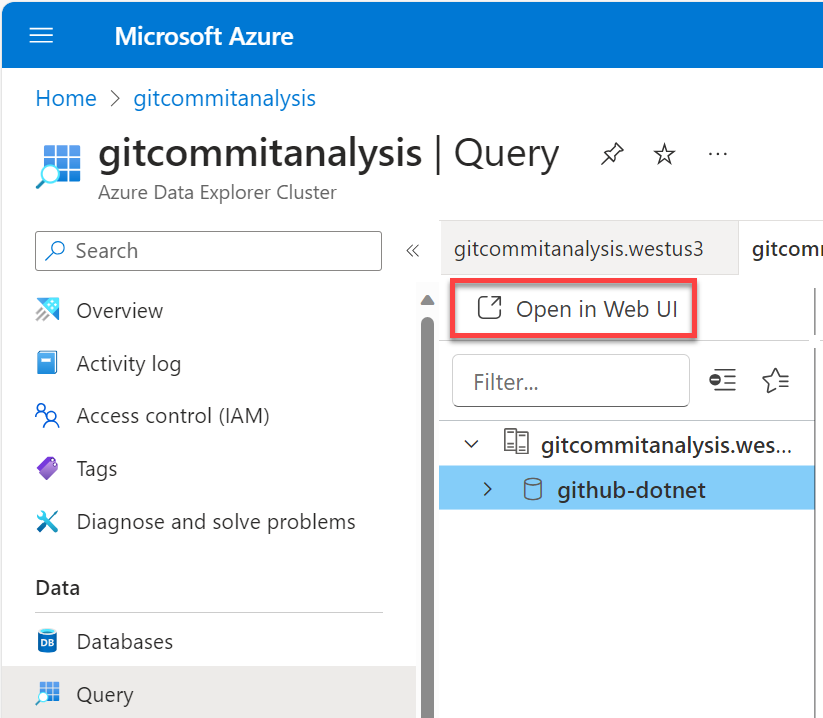
Once loaded, right-click on the database you created and then from the menu select Create table.
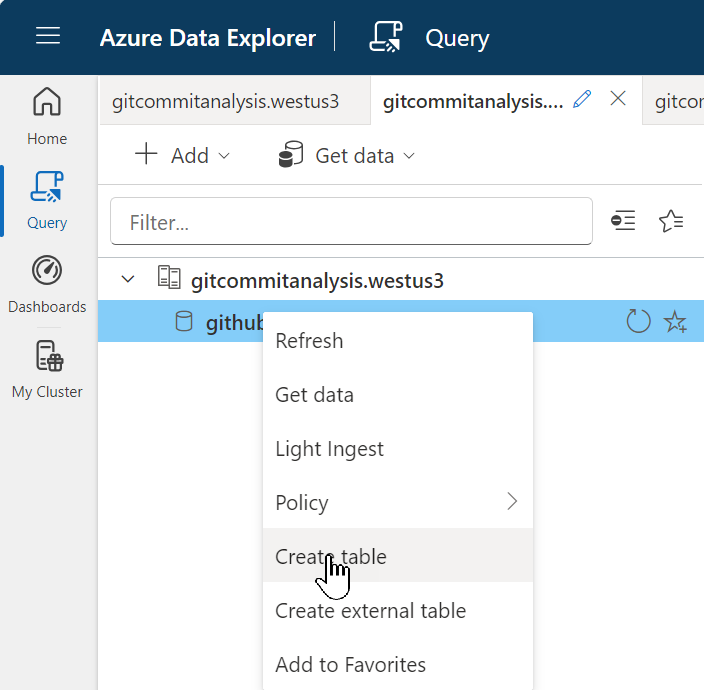
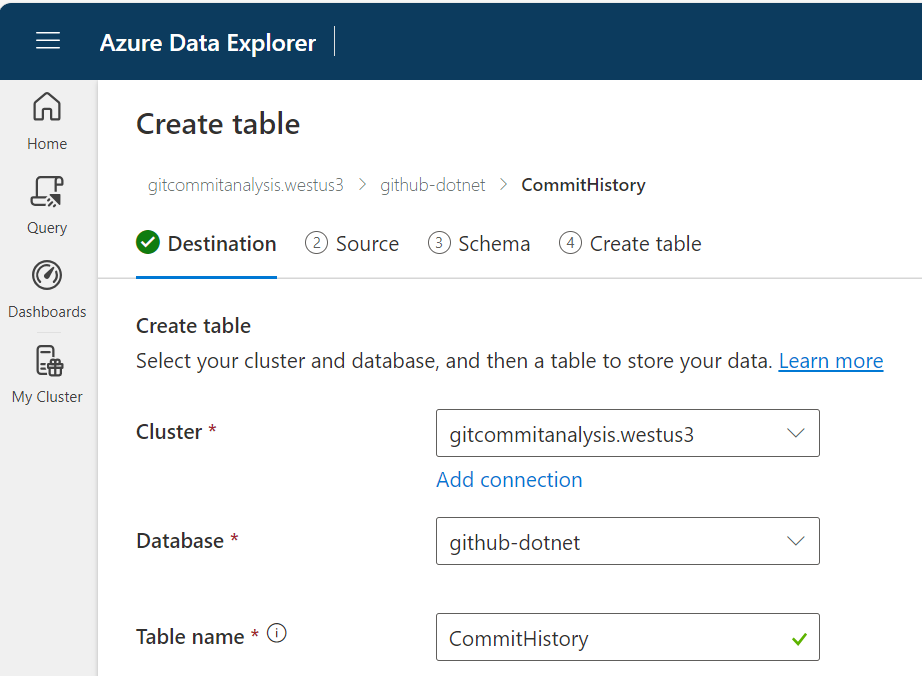
First, let's create a table called CommitHistory and import the history.json file.
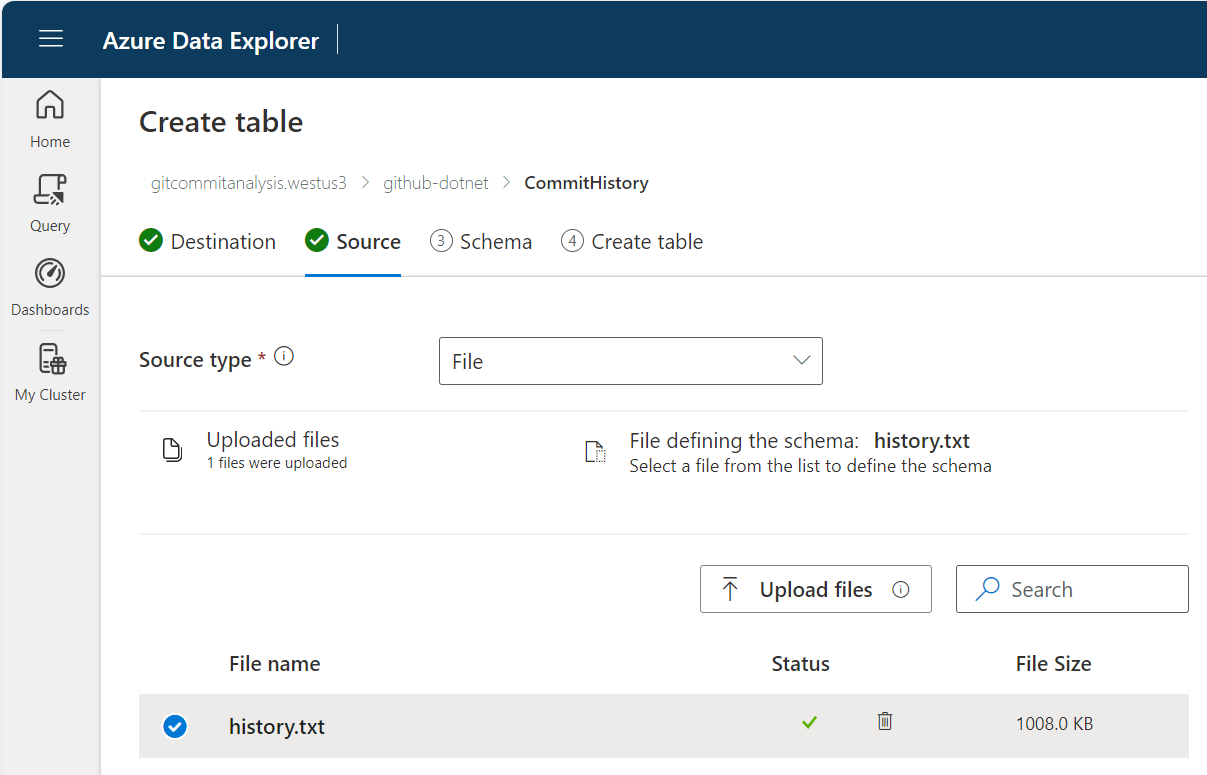
Import the file from earlier.
Now comes the important bit - we need to define the schema for the file we are importing. In the case of our history.json file we need to flatten the structure to ensure the author and commiter details are included. We do this by selecting Nested levels and setting it to 2. Make sure to select Ingest data to actually bring in the data.
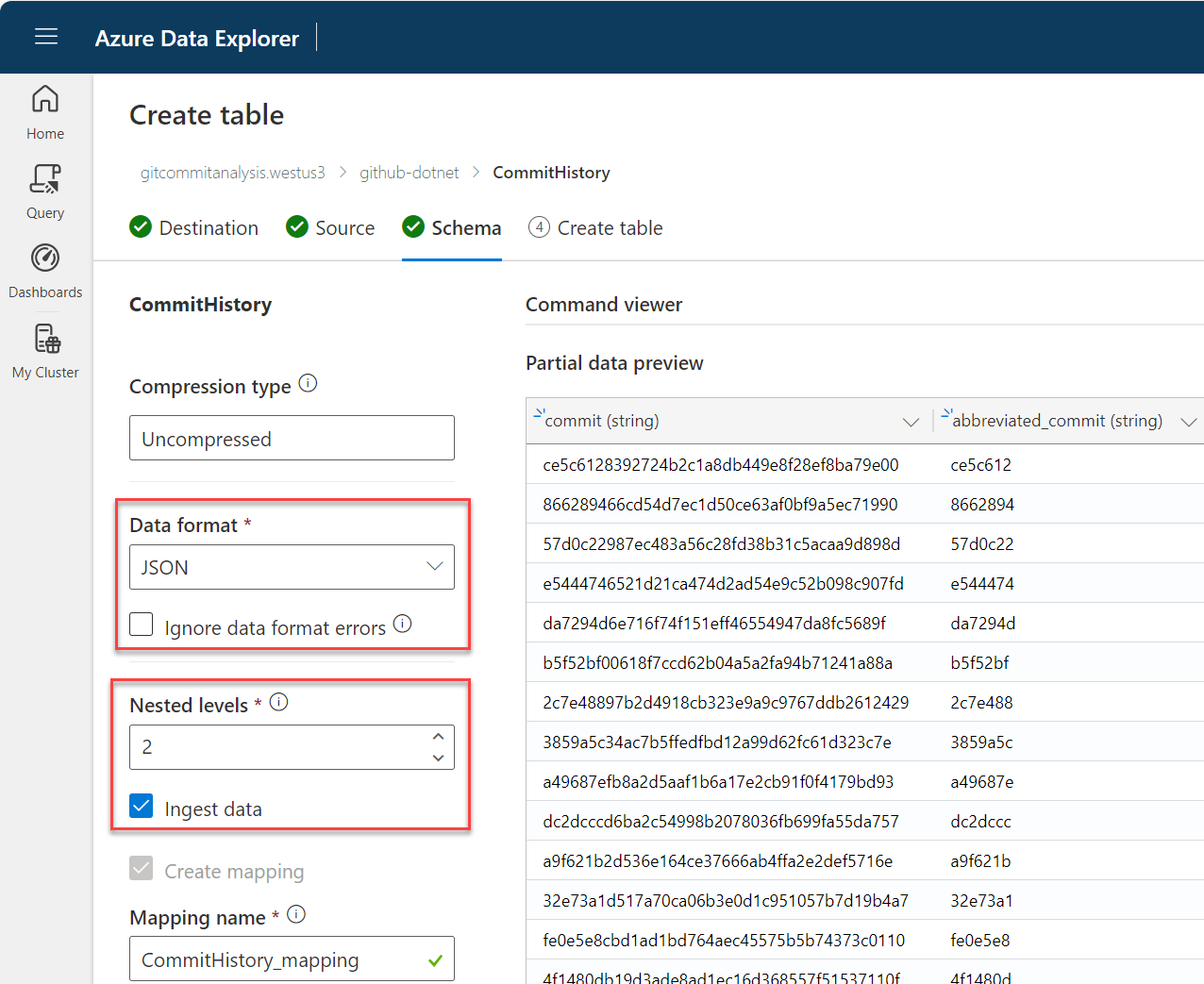
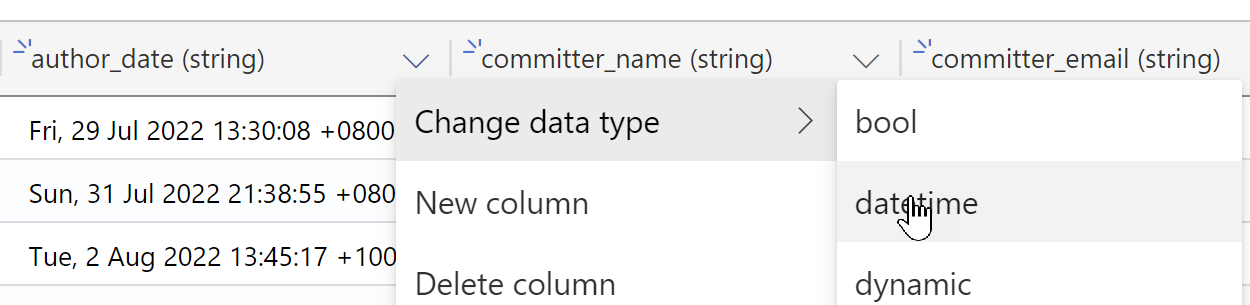
Additionally, you need to make sure that the data type for the date fields for author and committer are defined as a datetime data type.
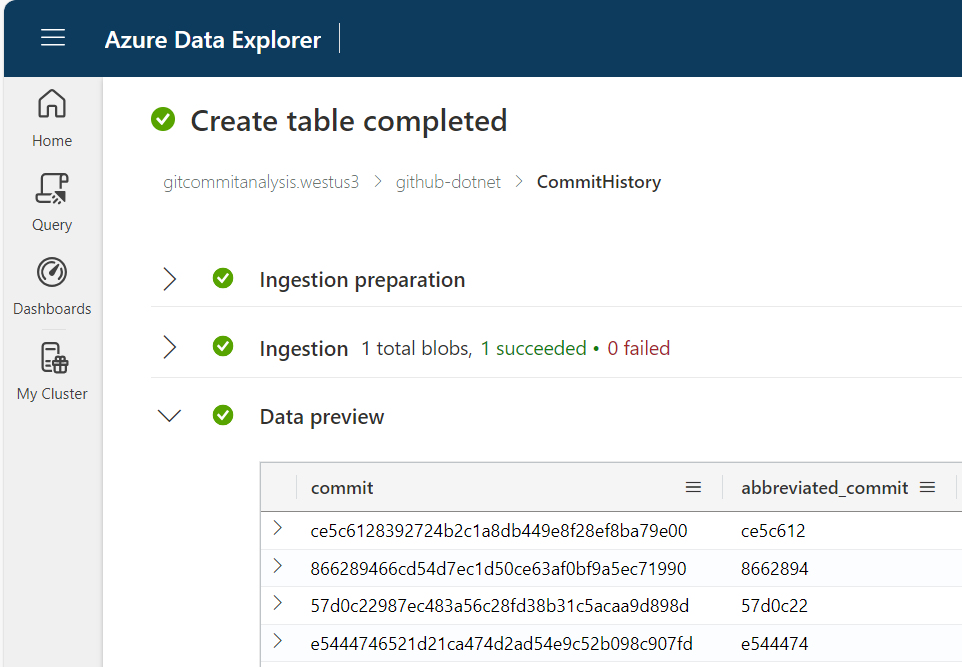
Finally, we can go ahead and import the data.
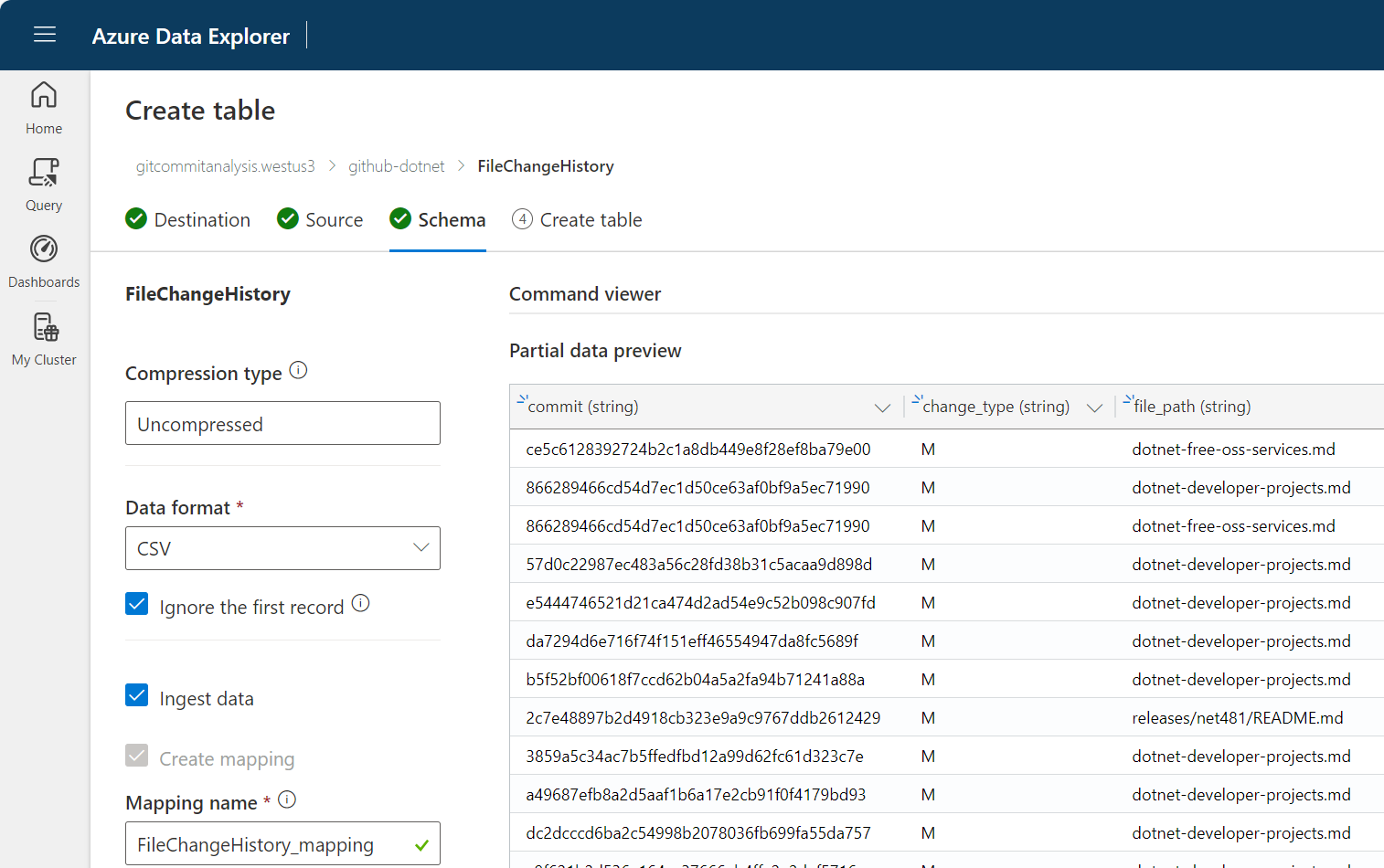
We also need to import the CSV data we created by parsing the file history dump from git. The process is essentially the same as above, except when we define the schema. You can see the settings below.
Now that we've imported our data, let's go ahead and do some analysis!
Anaylsing your git commit history
If you haven't used KQL (Kusto Query Langauge) before, it's probably worth doing the Microsoft Learn introduction to familarise yourself with its capabilities. It's a vey rich analysis language with the ability generate some good visualisations.
I will drop a few samples below, but at this point there are a range of directions you can go.
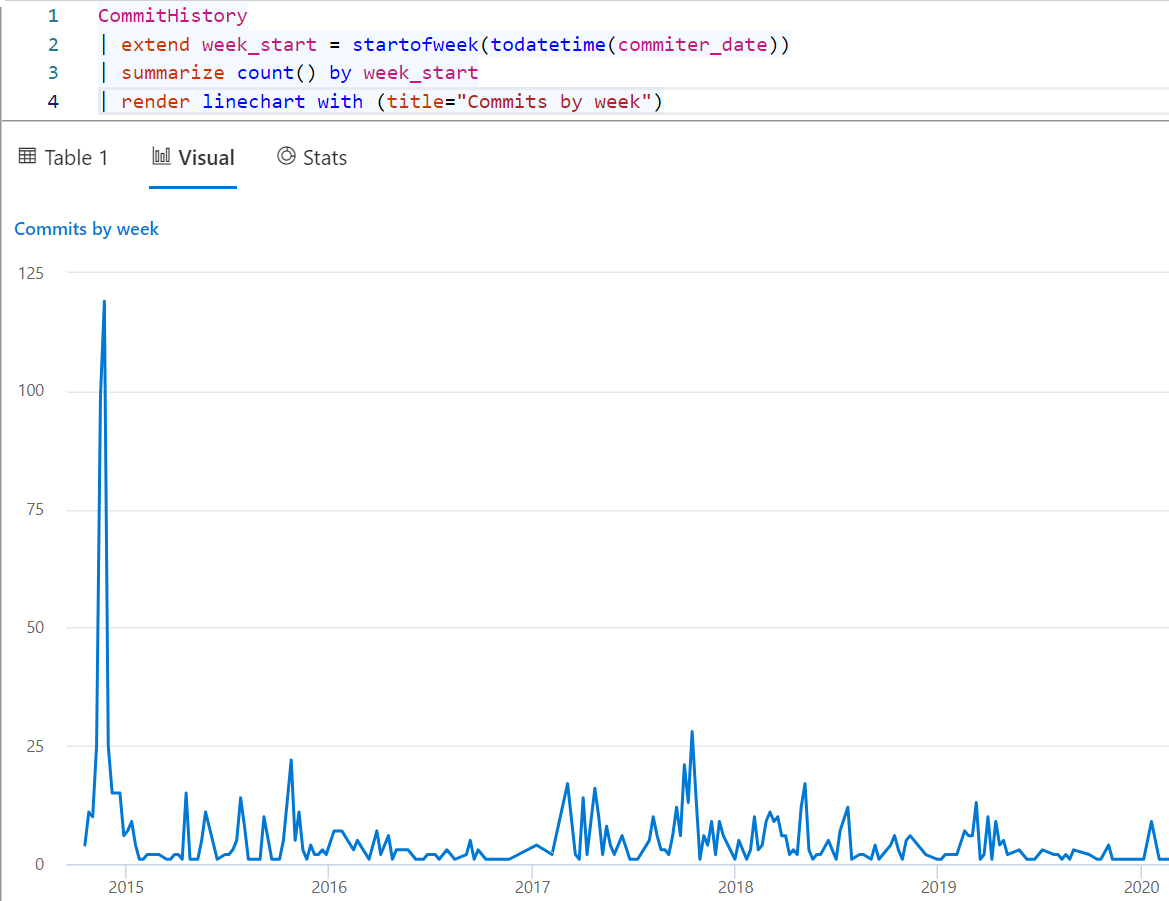
CommitHistory
| extend week_start = startofweek(todatetime(commiter_date))
| summarize count() by week_start
| render linechart with (title="Commits by week")
I've snipped the right-hand side of the graph, but even visualising the commits of the main .NET GitHub repository suggests that in the early days the team worked mostly on main, or was working rapdily to bring the codebase to a point they were happy and pushing to main often. 2017 to midway through 2018 was also super busy which aligns with the relase of .NET Core 2.0 and 2.1 and which was a time where the "new" .NET release really matured.
One more sample - let's take a look at top committers over time. The timeline view in Azure Data Explorer has a limit of 100 records, so let's pick a window of time where we won't break that limit (or have to use a limit clause in our KQL). I've also filtered out the GitHub user which is the result of an automation on GitHub's side. If we inspect the author for these commits we can see the orginal author of the commit (assuming the change wasn't entirely the result of a GitHub automation of some sort).
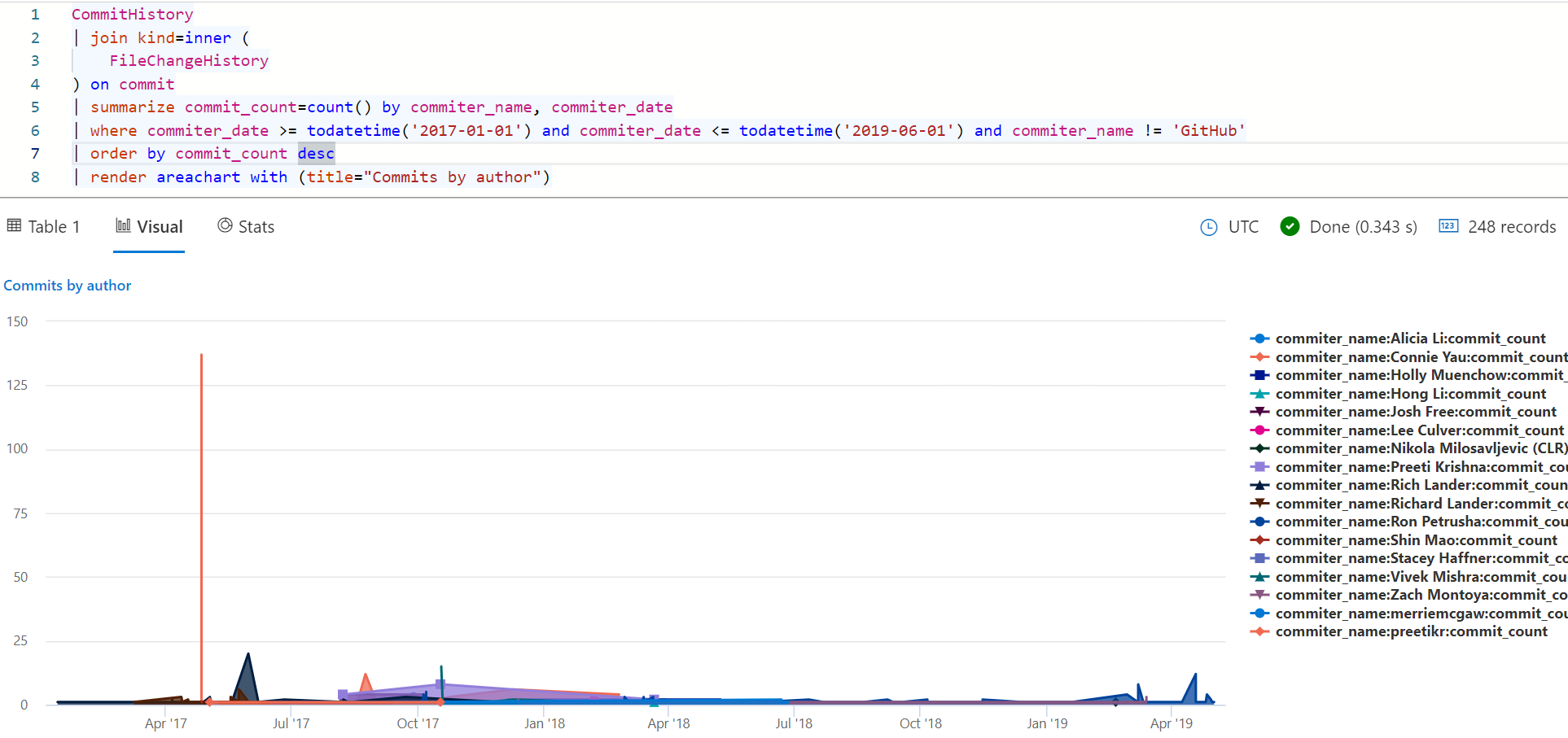
CommitHistory
| join kind=inner (
FileChangeHistory
) on commit
| summarize commit_count=count() by commiter_name, commiter_date
| where commiter_date >= todatetime('2017-01-01') and commiter_date <= todatetime('2019-06-01') and commiter_name != 'GitHub'
| order by commit_count desc
| render areachart with (title="Commits by author")
At this point, the world is our oyster as we now have the data in two tables and can query as we want - summarising and filtering to our heart's content.
What's next?
In an ideal world you would periodically ingest updated data dumps from your repository using a custom integration using the Azure Data Explorer built using an SDK such as the .NET one, and then build a dashboard using one of the available options.
I've created a GitHub repository to capture any KQL samples you might want to add that can benefit anyone doing git commit analysis using Azure Data Explorer.
Happy Days! 😎